Can AI Detection Do Better

As large language models revolutionize natural language processing, there is an increasing need for robust detection methods to distinguish between AI-generated and human-written text.
The recent growth of large language models has led to an increase in the presence of AI-generated content on platforms. To maintain authenticity and prevent the spread of misinformation, it has become crucial to develop detection methods. DetectGPT and similar works have made progress in identifying machine-generated text using probability analysis. For the final project of CPSC 588 AI Foundation Models at Yale University, our group investigated and aimed to improve the existing model’s performance in detecting AI-generated sentences.
We first hypothesized that substantial differences exist in statistical features between AI-generated and human-written text, including factors like readability and Part-of-Speech tag distribution. We, therefore, enhanced the pre-trained RoBERTa model by integrating statistical features of the input text into its classification architecture. Specifically, our model, implemented as RoBERTa Classifier, utilizes either early or late fusion techniques to combine the RoBERTa base model’s output with a non-linear transformation of statistical embeddings.
However, as pointed out in the work by Sadasivan et al., existing methods can be easily attacked by paraphrasing the text. This revelation suggests that adversaries can exploit this weakness to disseminate machine-generated misinformation that evades detection. Therefore, we introduced a novel adversarial learning component, LLM Attacker, which uses GPT-3.5-turbo as an additional resource to make the classifier more robust. This component challenges our model by providing adversarial examples during training, enhancing its detection capabilities. Our training regime involves processing both the original and adversarial examples, with the model dynamically adjusting to adversarial manipulations.
The project is a collective effort with Iris Wang and Andrew Yi. The methodology and findings of our project are documented and accessible on Github.
Title image source: https://www.tradoc.army.mil/social-media-fake-news/.
Methodology
Statistical Embeddings
In this project, we have adopted a concept similar to that presented in Heo et al.’s paper and have implemented statistical embeddings to enhance the input data. These statistical embeddings are generated by summarizing various statistics or characteristics of the input text, then transforming and combining them into embedding vectors. These additional embeddings prove to be beneficial in identifying machine-generated text, as the distribution of such underlying statistics may vary between human-written and machine-generated texts. The statistical embeddings are integrated with the input embeddings, as illustrated in Figure 1.
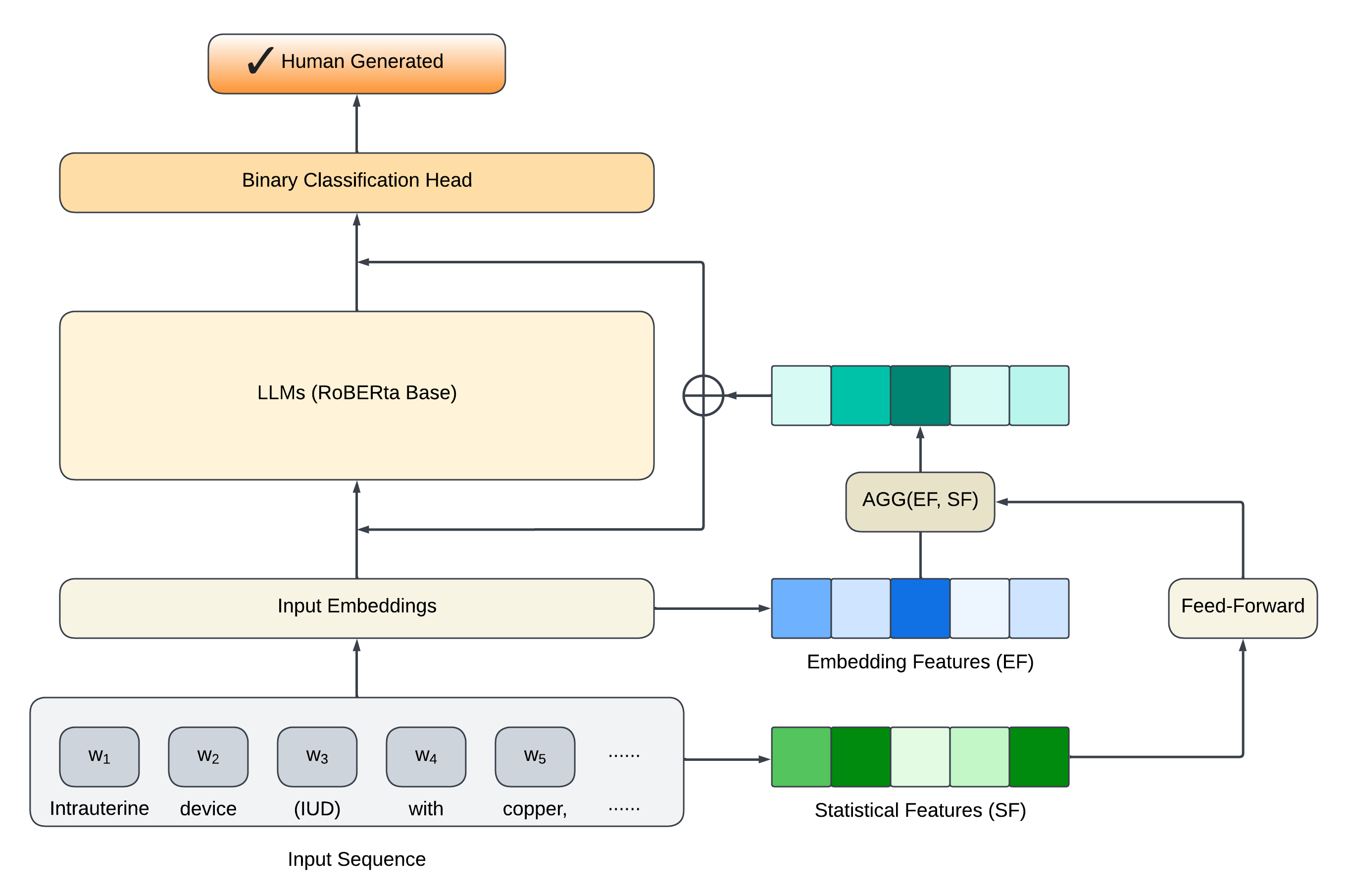 Figure 1: Statistical Embedding
Figure 1: Statistical Embedding
Part-of-Speech Tag Distribution: The first statistical feature we integrated is the distribution of Part-of-Speech (PoS) tags in the input text. PoS tags are labels assigned to each word in the text, categorizing them into classes such as nouns, verbs, and adjectives. We hypothesize that the distribution of PoS tags could differ between human-written and machine-generated texts, making it a potential indicator in the detection process. We utilized the Natural Language Toolkit (NLTK)’s PoS tagger to classify each word in the input text into its corresponding PoS category. The tagger employs a total of 45 PoS tags, including 9 for punctuation and special characters. When summarizing the PoS tag distribution of an input text, we excluded tags designated for punctuation and special characters. The frequency counts of the remaining 36 categories are then normalized to form a PoS tag frequency distribution. This distribution is represented as a 36-dimensional vector and is used as a statistical embedding.
Readability Metrics: Another significant characteristic of text is its readability metrics. We postulate that human-written and machine-generated texts should, on average, exhibit different readability scores, thus serving as another useful indicator for detecting machine-generated texts. To measure the readability scores of input texts, we employed the py-readability-metrics package, which includes eight different metrics: Flesch Kincaid Grade Level, Flesch Reading Ease, Gunning Fog Index, Dale Chall Readability, Automated Readability Index, Coleman Liau Index, Linsear Write, and SPACHE. The package requires the text to contain at least 100 words. Therefore, for input texts shorter than 100 words, we simply repeat the text until the minimum word count is achieved. This padding method ensures the consistency of the structural and semantic information within the texts. The readability statistical embeddings for an input text are generated by calculating the eight different scores using the aforementioned metrics. These scores are then directly used as an 8-dimensional vector embedding for the text.
Early / Late Fusion
For our model, we adapted the early and late fusion paradigms, drawing inspiration from Heo et al.’s work. We implemented these paradigms by introducing modifications to the RoBERTa Classifier model. This model supports both fusion techniques through its architecture, which integrates a RoBERTa-based transformer with statistical embeddings. The detailed model structure is shown in Figure 2.
In the early fusion approach, we directly used the appoarch described in the original paper. We combine the statistical embeddings and the input embeddings at an initial stage. This is achieved by aggregating the transformed statistical embeddings directly with the RoBERTa model’s pooled output. Specifically, a non-linear transformation, using a ReLU activation, is applied to the statistical embeddings. These transformed embeddings are then concatenated with the RoBERTa pooled output before being fed into a unified classifier. This classifier is a linear layer that maps the concatenated features to the final output dimensions.
Conversely, in the late fusion model, we made a couple of adjustments. The input embeddings and statistical embeddings are processed separately through distinct pathways. Initially, the RoBERTa transformer processes the input embeddings, and a non-linear transformation is applied to the statistical embeddings, similar to the early fusion model. However, in late fusion, these pathways diverge: the transformed statistical embeddings are passed through a separate classifier, and the RoBERTa output is conditioned by applying a sigmoid-activated conditional layer based on the statistical embeddings. The output logits from the RoBERTa pathway and the statistical embeddings classifier are then aggregated to produce the final output.
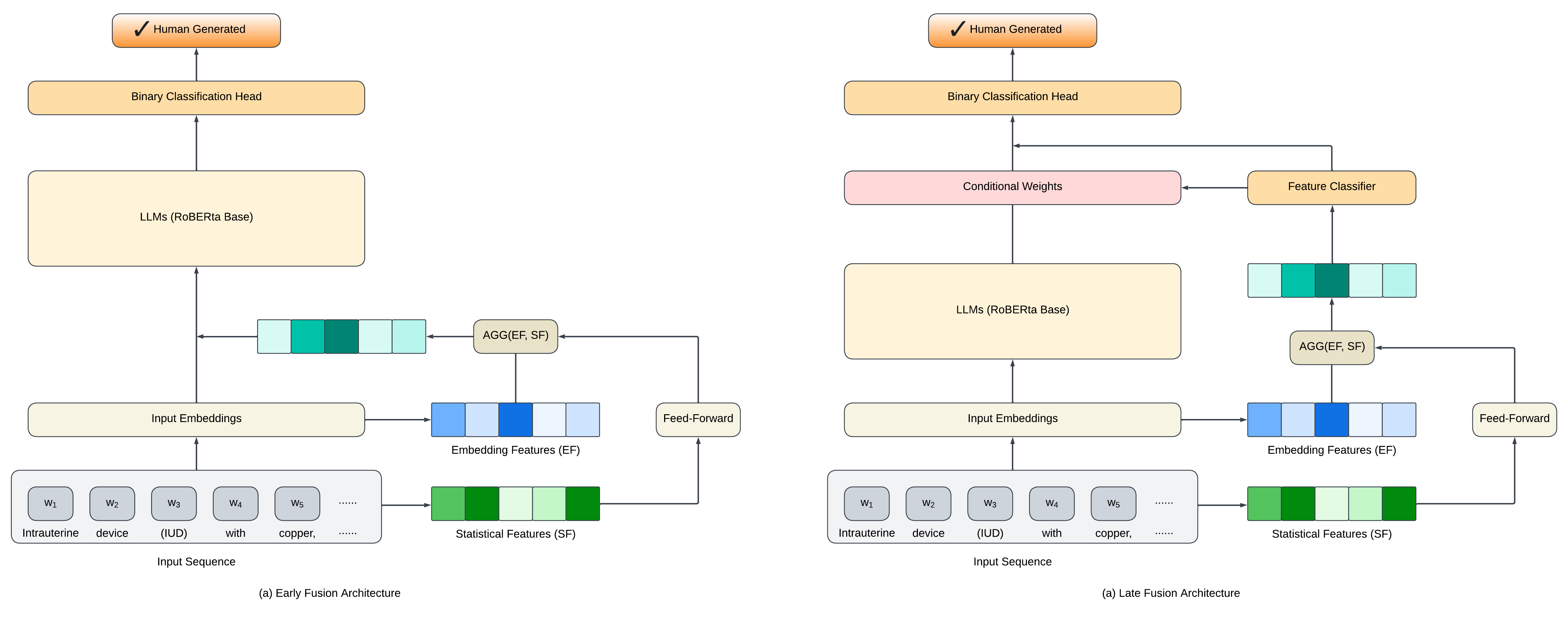 Figure 2: Model Fusion Process
Figure 2: Model Fusion Process
Attacker
Our project also introduces an advanced adversarial learning component designed to enhance the robustness of our RoBERTa Classifier, which integrates both statistical and embedding features. The core of our adversarial approach relies on the use of Large Language Models (LLMs), specifically leveraging the capabilities of GPT-3.5-Turbo through the OpenAI API.
Attacker Model
Our attacker model operates as follows: Once a prediction is made by the RoBERTa Classifier, the standard backward propagation loop is employed for incorrect predictions. However, for correct predictions, the attacker model comes into play, aimed at further refining the model’s performance.
The attacker model is initialized with GPT-3.5-Turbo. As shown in Figure 3, it employs two modes of operation—paraphrasing and in-context learning. For inputs that are machine-generated and correctly identified as such by the classifier, the attacker model engages in paraphrasing the input text using the GPT-3.5-Turbo model. This step is crucial for the model to learn defenses against paraphrasing attacks, potentially aiding in generalization to broader contexts.
Conversely, when the classifier accurately identifies an input as human-generated, our attacker model engages in in-context learning. In this process, GPT-3.5-Turbo is employed to subtly modify the original text, aiming to preserve its inherent characteristics. This approach is designed to present a more intricate challenge to the classifier, testing its ability to discern nuanced alterations while maintaining the essence of the original text. It’s important to note that our initial strategy involved leveraging the extracted statistical features to guide the LLM in replicating a style closely aligned with the original. However, due to time constraints and complexities in translating numerical statistical features into effective prompts, this aspect was not implemented in the current study. Consequently, the integration of statistical features in this context remains unexplored, and we acknowledge it as a potential avenue for future research.
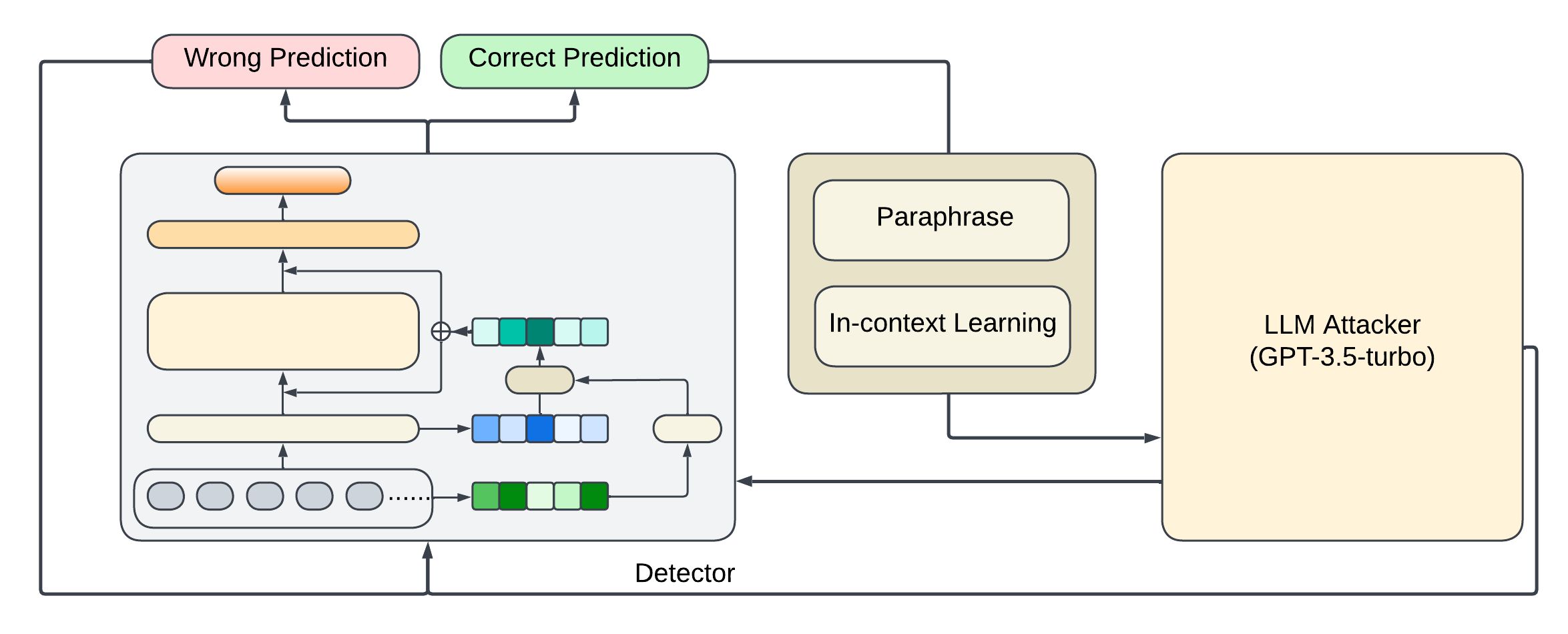 Figure 3: Overall Architecture
Figure 3: Overall Architecture
Training Details
The integration of this adversarial learning component is seamlessly embedded within the training loop of the RoBERTa Classifier model. The train epoch function, an integral part of our training pipeline, incorporates the adversarial examples generated by the attacker model when the classifier model makes a correct prediction. In such instances, the adversarially modified text, along with its corresponding labels, is seamlessly merged with the original dataset. This amalgamation feeds into a revised loss function, which is then utilized for further model training. This approach is designed to enhance the classifier’s learning curve by exposing the model to both its initial predictions and the adversarially altered examples, aiming to make the trained model more robust to the potential of paraphrasing attacks.
Experiment
Data
We used two widely recognized datasets for the training and testing of the model. The first, the GPT-Wiki-Intro dataset, contains human-written and GPT-3 generated introductions for 150k Wikipedia topics. We randomly selected 1700 examples for training, 150 for validation, and another 150 for the test set. We then preprocessed the data by truncating both human- and AI-generated texts to the same length.
We also included the PubMedQA dataset, a benchmark biomedical research question-answering dataset with human-labeled and artificially generated QA instances. We extracted the long answers written by humans and machines from the PubMedQA dataset. Next, we randomly selected the same number of samples for training, validation, and testing as for the GPT-Wiki-Intro dataset.
Baseline Model
For the baseline model, we utilized a pre-trained RoBERTa Classifier and ran 5 epochs for each dataset. The optimizer is Adam with a learning rate of 2e-5. The loss function is cross entropy loss, which is defined as
where loss_fn represents BCE Loss. The evaluation metric is accuracy.
Statistical Embeddings
The subsequent experiments were conducted with the inclusion of statistical embeddings on top of the baseline model. Additional embedding and classification layers were incorporated for the statistical embeddings, following both early and late fusion architectures.
Recall from previous discussions that two distinct statistical embedding methods were developed: one for Part-of-Speech (PoS) tag distributions and another for readability metrics. Consequently, for each dataset, three distinct experiments were executed incorporating PoS features only, readability features only, and a combination of both features. When combining both features, their corresponding statistical feature embeddings were concatenated to form a composite higher-dimensional embedding vector.
Initially, experiments were conducted using the early fusion approach. Subsequently, the model was configured for late fusion, and all aforementioned experiments were replicated. This resulted in a total of six experiments for cross-comparison to assess the efficacy of each statistical embedding type. The baseline model’s optimizer, loss function, and evaluation metric were employed throughout.
Attacker Model
In the final phase, the attacker model was integrated into the training process. The inclusion of the attacker component was methodically tested across the six models, which varied in terms of statistical embeddings (PoS features, readability features, and their combination) and fusion techniques (early and late fusion).
Moreover, the experimentation was expanded to include more complex prompts, aimed at enhancing the attacker model’s capability in generating a wider array of adversarial examples. These intricate prompts were designed to elicit more nuanced responses from the AI.
Results
The accuracy of the baseline model on two datasets is presented in Table 1 below. The accuracies of the early and late fusion models with statistical embeddings and the attacker model are displayed in Table 2 and Table 3, respectively. Given the baseline model’s near-perfect accuracy of 0.999 on the Wiki Intros dataset, the focus of our analysis was directed towards the PubMedQA dataset.
| Model | Wiki Intros | PubMedQA |
|---|---|---|
| Baseline | 0.999 | 0.740 |
Table 1: Baseline Model Accuracies on Two Dataset
| Model (Early Fusion) | Wiki Intros | PubMedQA |
|---|---|---|
| Baseline + PoS | 0.999 | 0.740 |
| Baseline + Readability | 0.999 | 0.747 |
| Baseline + (PoS + Readability) | 0.999 | 0.660 |
| Baseline + PoS + Attacker | 0.997 | 0.793 |
| Baseline + Readability + Attacker | 0.999 | 0.725 |
| Baseline + (PoS + Readability) + Attacker | 0.999 | 0.779 |
| Baseline + PoS + Attacker + Detailed Prompt | 0.999 | 0.801 |
Table 2: Early-Fusion Model Accuracies on Two Datasets
| Model (Late Fusion) | Wiki Intros | PubMedQA |
|---|---|---|
| Baseline + PoS | 0.999 | 0.700 |
| Baseline + Readability | 0.999 | 0.633 |
| Baseline + (PoS + Readability) | 0.999 | 0.693 |
| Baseline + PoS + Attacker | 0.999 | 0.786 |
| Baseline + Readability + Attacker | / | 0.734 |
| Baseline + (PoS + Readability) + Attacker | / | 0.769 |
| Baseline + PoS + Attacker + Detailed Prompt | / | 0.819 |
Table 3: Late-Fusion Model Accuracies on Two Datasets
Please note due to limited time and resources, we were unable to complete all experiments on the Wiki-Intro Dataset.
Statistical Embeddings
The incorporation of statistical features led to a noticeable improvement in validation accuracy over the baseline metrics, as evidenced by the results in the aforementioned tables. This consistent enhancement suggests that the designed statistical features effectively serve as indicators of machine-generated texts, and the integration of statistical embedding layers enhances model performance.
Furthermore, the incorporation of either PoS distribution or readability metrics alone resulted in comparable improvements in validation accuracy for both early and late fusion. However, the combination of both PoS and readability information did not yield performance improvements as anticipated. This unexpected outcome could be attributed to a mismatch in the magnitude of the features/metrics. The normalization of these features might require a more suitable method to ensure higher stability.
Attacker and Detailed Prompt
The performance of the model was further improved by the addition of an Attacker Model and the use of more detailed prompts. Similar to previous findings, the inclusion of both PoS and readability features appeared to detract from performance. Consequently, only PoS embeddings were incorporated into the overall model alongside the Attacker and detailed prompting, as this combination showed superior performance in conjunction with the Attacker model compared to readability embeddings. The comprehensive model achieved a validation accuracy of 0.823 and a test accuracy of 0.819, significantly surpassing the baseline metrics and achieving the best result among all conducted experiments.
Conclusion and Discussion
Our research demonstrates that the integration of statistical embeddings, specifically Part-of-Speech tag distribution and readability metrics, along with the extension of the attacker model, leads to improved accuracy in detecting AI-generated text. Although the model consistently achieves near-perfect accuracy on the Wiki Intros dataset, the late fusion model’s performance on the PubMedQA dataset consistently outperforms the corresponding early fusion model.
A limitation of our approach is that readability metrics may be less effective for short sentences, particularly for inputs significantly shorter than 100 words. In such instances, simply repeating the text to meet the minimum word count may not accurately reflect changes in readability.
Initially, we planned to include additional embedding features, such as characteristics derived from the input embeddings rather than the raw input texts. One potential feature was the concept of intrinsic dimension, as introduced in Tulchinskii et al’s paper. However, the application of intrinsic dimension to individual data points, as opposed to a sizable collection of points, presents challenges. We are exploring effective ways to incorporate this concept into the model, and future work could consider including this and other embedding features to further enhance model performance.
Future research should also focus on incorporating higher quality and quantity training data from various domains to improve the model’s generalizability and robustness in detecting AI-generated text.