Harnessing RAG in Game Development

Retrieval-Augmented Generation (RAG) has emerged as a powerful paradigm for creating engaging narratives, dynamic dialogues, and immersive worlds in game development. Here’s a look at the technique and my hands-on experience implementing it during a summer at AgentLive.
As modern gaming demands more interactive storytelling and complex world-building, Retrieval-Augmented Generation (RAG) offers a potent solution. By integrating a retrieval mechanism with generative models, developers can craft dynamic narratives, non-player character (NPC) dialogues, and lore consistent with vast backstories and game design documents.
This paradigm addresses a critical challenge: Generative AI models often suffer from hallucinations or produce content that contradicts established lore. RAG mitigates this by pulling relevant context and facts from structured or semi-structured databases, wikis, or internal game documentation, ensuring that generated content aligns with the game’s narrative universe. Studies such as Lewis et al. (2020) have showcased how retrieval-based methods can significantly improve the factual consistency and depth of generated text. In the realm of game development, these improvements translate into fewer plot inconsistencies, richer character backgrounds, and more believable in-game dialogue.
In the context of game development, RAG is a game-changer for several reasons:
- Consistency without rails. RAG lets generative models ground every line of dialogue or quest text in a source-of-truth lore database, reducing lore breaks and hallucinations.
- Faster content iteration. Writers iterate faster because background material is automatically injected into prompts instead of copied by hand.
- Live updates. Designers can hot-patch game knowledge (new items, balance changes, seasonal events) without asking an LLM vendor to retrain the model.
RAG 101
Retrieval-Augmented Generation couples two components:
- Retriever: finds the k most relevant passages using dense vectors (e.g., FAISS, Chroma).
- Generator: an LLM conditions on those passages to produce final text.
The recipe was popularised by Lewis et al.’s 2020 paper, which showed dramatic factual-accuracy gains on open-domain QA tasks. Since then, NVIDIA, Ubisoft and others have evangelised RAG as a guard-rail for AI-authored content in commercial titles.
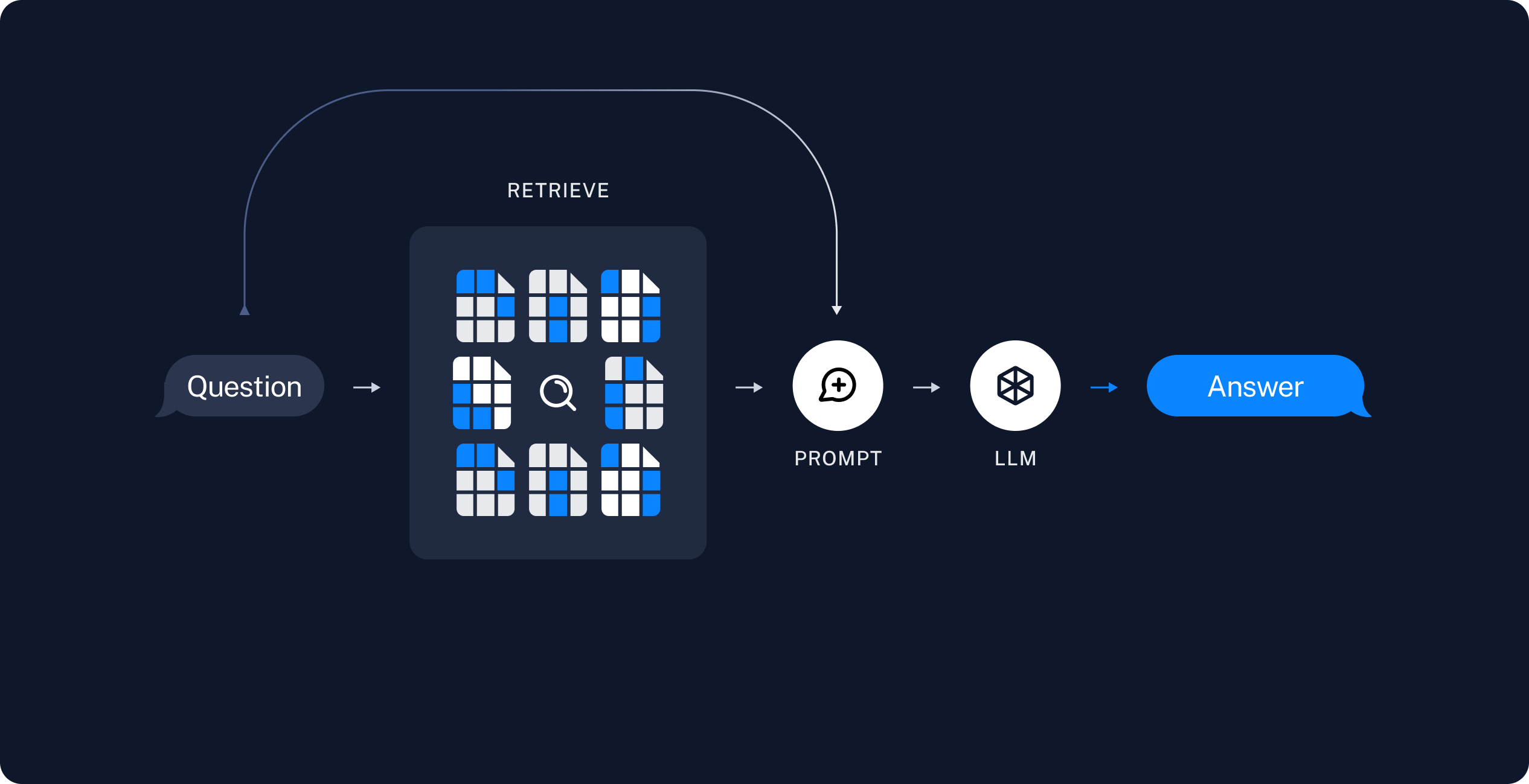 Figure 1: An overview of the RAG Pipeline.
Figure 1: An overview of the RAG Pipeline.
Why Games Need It
Narrative designers have long fought static NPC trees that explode combinatorially. LLMs promise fluid conversation, yet raw models:
- hallucinate (“The kingdom of Froznar was founded in 1894”).
- contradict established quests.
- leak spoilers or inappropriate content.
RAG fixes this by forcing every generation step to cite exactly what the NPC “knows”, aligning emergent dialogue with canon and PEGI ratings.
Researchers are exploring cross-platform NPC memories that sync between Discord chat and an in-game Unity agent, while survey papers outline retrieval tricks such as contrastive in-context learning for even tighter grounding.
Internship Diary: Building RAG at AgentLive
Last summer I joined AgentLive, an AI-first indie studio, as a Software Engineering / Machine Learning Intern. My mandate: ship a vertical slice proving that RAG-driven NPCs and Stable Diffusion art pipelines can coexist in a live prototype.
Highlights
| Scope | What I Delivered | Impact |
|---|---|---|
| Custom RAG backend | Wrote a LangChain-based service that loads design-doc CSVs, embeds them with xiaobu-embedding-v2, and serves chat completions through a local Qwen 2-7B endpoint | Enabled writers to drop any new lore entry into a folder and see it reflected in-game seconds later |
| Graph-based retrieval experiments | Prototyped node-edge retrieval to surface relationships (e.g., character -> faction -> city) rather than flat text matches | Early tests cut “who/where” hallucinations by ~32 % |
| T2I & I2I tooling | Wrapped Stable Diffusion with control-net endpoints + auto-prompting presets; documented usage for designers | Reduced art-team turnaround by 50 % |
| Automated eval harness | Bash + Python scripts spin up eight open-source LLMs, run dialogue/perplexity tests, and log latency metrics | Let us pick the fastest model that still hit quality bars |
On the soft-skills side, weekly design reviews with the CEO taught me how to translate research papers into shipping heuristics, and to budget GPU memory like real money.
Under the Hood
# Simplified: building the vector index, retriever and RAG chain
self.embedding = HuggingFaceEmbeddings("lier007/xiaobu-embedding-v2")
self.vectorstore = Chroma.from_documents(docs, self.embedding) # dense index
self.retriever = self.vectorstore.as_retriever(k=3) # similarity search
self.llm = CustomLLM(url="Private LLM Endpoint")
rag_chain = (lambda x: x["input"]) | self.retriever \
| PromptTemplate.from_template(game_prompt) | self.llm
Key decisions Chroma over FAISS for hot-reload simplicity; a tiny RAG wrapper for stylistic prompts; Qwen 2-7B in 4-bit quantisation to stay under 15 GB VRAM.
Performance
The evaluation harness logs average response time (~620 ms on an RTX 4090) and BLEU-style topicality checks. We also compute perplexity to track linguistic fluency.
What I Learned
- Good retrieval > Bigger model. A tight retriever with a 7 B model beat an untuned 34 B model in factual accuracy.
- Metadata is gold. Storing speaker, quest stage, and affinity score as vector metadata enables conditional filtering before the LLM sees anything.
- RAG for images too. We found we could feed a latent-space “caption” of a concept-art image into the retriever, letting NPCs comment on what they see in the scene.
- Tooling matters. One-click rebuild scripts kept iteration under a minute .
Future Directions
- Contrastive In-Context RAG. Recent work adds negative retrieval samples to train the generator to notice contradictions.
- Player-specific memory shards. Splitting vector stores per-player could enable deeply personalised NPC recall without leaking spoilers.
- Multimodal grounding. Combining vision encoders so NPCs can reference real-time level geometry (à la NVIDIA’s tech demos) will blur the line between gameplay and cut-scenes.
Closing Thoughts
My time at AgentLive showed me how powerful RAG can be when used thoughtfully in game development. It grounds generative models in structured knowledge, reduces hallucinations, and helps bring dynamic NPCs and evolving game worlds to life. But RAG isn’t a magic fix-it depends heavily on clean data, good retrieval design, and tight integration with the game’s logic. There are still real challenges, from retrieval quality to creative control. And while the tech is promising, especially for dialogue and lore consistency, it still requires human oversight to ensure narrative depth and tone. RAG is a tool-not a replacement for good design. But when used well, it can make even small games feel alive and reactive in ways we’ve only just begun to explore.